Due date: Mar 5, 2019
Introduction
- In this exercise you’ll be working with the two readings posted on the library’s e-reserve page that were assigned for this class.
- This exercise is worth 6 points. Part I is worth 3 points and Part II is worth 3 points.
- As this assignment does not require SQL statements, the normal SQL submission guidelines do not apply. You can submit the responses in MS Word format.
Part I – ER Diagram
Read and refer to the Entity Relationship Model article by Song and Chen to answer the following questions. These three questions all refer to figure 3, which depicts a model for a company.
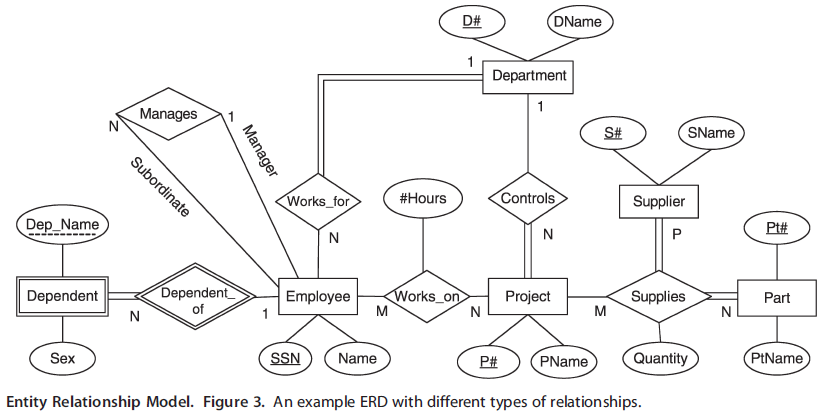
In figure 3 on page 1006, the relationship between the dependent (spouse or child of an employee) and employee is indicated by the relationship diamond “Dependent of”. Cardinality (direction of the relationship) is a one to many relationship as indicated by the number 1 for the dependent and letter N for employee. Participation is indicated by the lines that connect each entity to the relationship. The double lines from dependent indicate mandatory participation, while the single line from employee indicates optional participation. Thus, the relationship can be described:
A dependent is a dependent of an employee, because they receive health benefits through the employee. Dependents can only have one employee, because they can’t receive benefits from multiple people. Each dependent must have one employee, because they cannot receive benefits from the company if no family member works there. An employee may have many dependents, but does not have to have a dependent because they may have no immediate family members.
1. Based on this example, describe the relationship that exists between the employee and department entity. Model your answer on the quoted text above and address: what the relationship is, the logic behind it, cardinality, and participation. Use your imagination to express the logic behind the relationship, for example the reasons why an employee may or may not be assigned to a department.
2. Similar to question 1, describe the relationship that exists between the employee and project entity. Model your answer on the quoted text above and addresses: what the relationship is, the logic behind it, cardinality, and participation. Make sure to address the logic behind the realtionship.
3. The diagram has a department entity. Imagine you have to extend this model by adding an office entity, which represents distinct physical locations where all departments are located (based on the example below). Describe the relationship, cardinality, and participation between the department and office entity. In addition, provide two attributes that could be associated with the office entity.
- Department – Office
- Administration – New York Office
- Accounting – New York Office
- Sales – New York Office
- R & D – New Brunswick Office
- Human Resources – New York Office
- Manufacturing – Allentown Office
- Shipping – Allentown Office
Part II – Normalization
4-6. Referring to the slides and the article by Kreibich, take the following data on dependent territories (areas that are not independent countries but are controlled by other sovereign nations) and put it into 1st, then 2nd, then 3rd normal form. The region and continent indicate where the dependency is located (these are part of a hierarchical scheme the United Nations uses for classifying countries; regions fall within continents). Columns that begin with a ‘T’ refer to the territory while columns beginning with an ‘S’ refer to the sovereign nation that controls the territory.
Show each step of the transformation just as it’s demonstrated in the slides (1st, then 2nd, then 3rd), where the tabular outcome of each normalization phase is shown. Do not conflate any of the forms. You can copy and paste the table into Word, and use Word’s table functions to display each one, and under each result write one to two sentences describing what you did.
| Territory | Tcapital | Tpop | Tregion | Tcontinent | Sid | Sovereign | Scapital |
|---|---|---|---|---|---|---|---|
| Falkland Islands (FLK) | Stanley | 2,931 | South America | Americas | GBR | United Kingdom | London |
| Faroe Islands (FRO) | Torshavn | 49,188 | Northern Europe | Europe | DNK | Denmark | Copenhagen |
| Falkland Islands (FLK) | Stanley | 2,931 | South America | Americas | GBR | United Kingdom | London |
| French Polynesia (PYF) | Papeete | 285,735 | Polynesia | Oceania | FRA | France | Paris |
| Gibraltar (GIB) | Gibraltar | 29,328 | Southern Europe | Europe | GBR | United Kingdom | London |
| Greenland (GRL) | Nuuk | 56,483 | Northern America | Americas | DNK | Denmark | Copenhagen |
| Guam (GUM) | Hagatna | 162,742 | Micronesia | Oceania | USA | United States | Washington DC |
| Guernsey (GGY) | St Peter Port | 63,026 | Northern Europe | Europe | GBR | United Kingdom | London |